CalibPlan: The Missing Step Before Fine-Tuning Small Language Models

Most teams treat fine-tuning as the first serious step after prompt experiments.
That is often backwards.
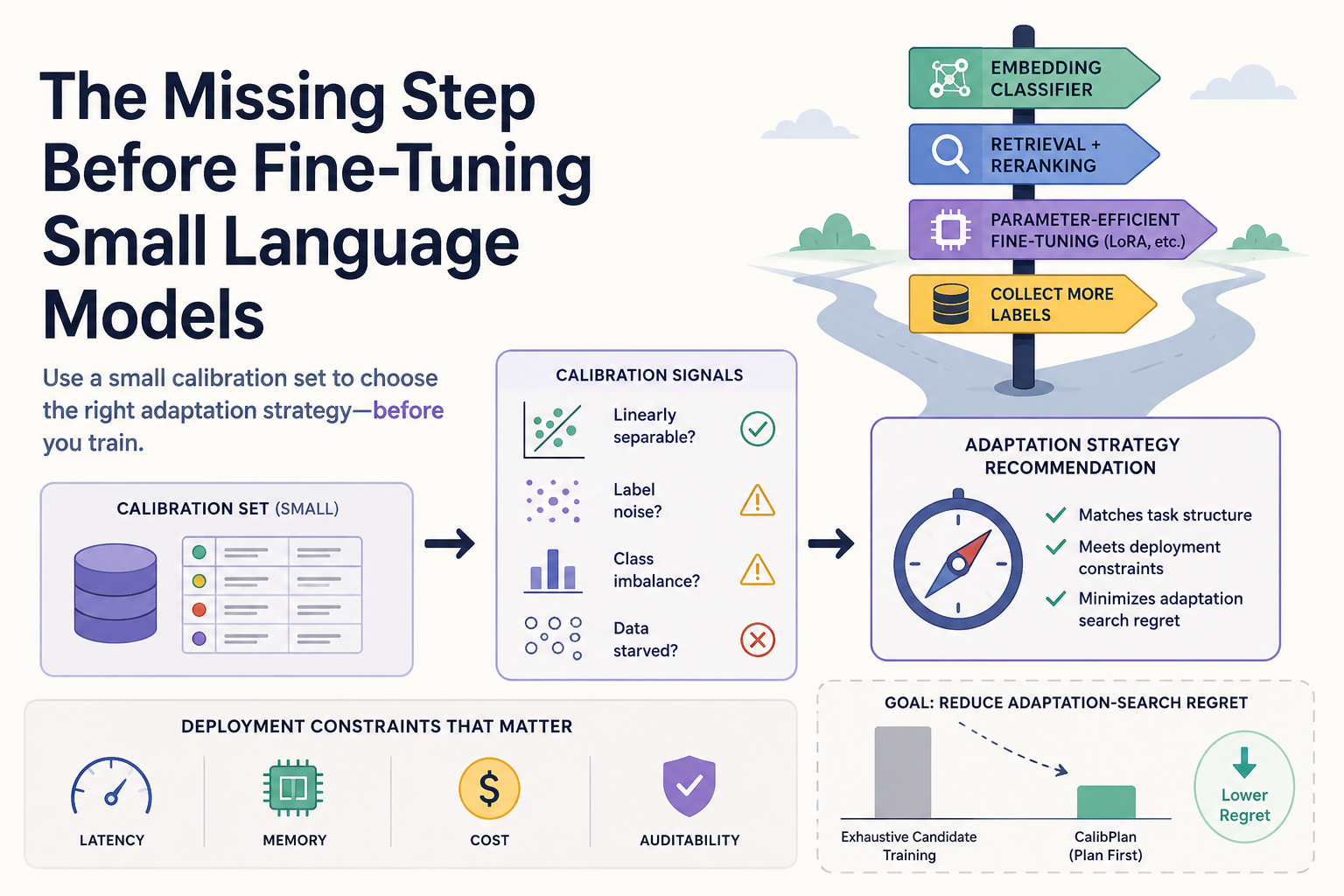
For narrow decision tasks, a small calibration set can reveal whether the task is linearly separable, label-noisy, class-imbalanced, or data-starved. Those signals should influence whether the next step is an embedding classifier, retrieval, parameter-efficient fine-tuning, or collecting more labels.
The expensive mistake is not only choosing the wrong LoRA rank. It is training several candidates before asking whether the task structure justified that search.
The Problem: Adaptation Search Without Direction
When you have a new task and a small language model, the natural instinct is to start training. But which approach?
- Full fine-tuning? Expensive in memory and latency.
- LoRA? Which rank? Which layers?
- Retrieval-augmented generation (RAG)? Only if your task benefits from external knowledge.
- Embedding classifiers? Fast, but only if the decision boundary is simple.
- Prompt engineering + in-context learning? Sometimes enough, but how do you know?
Most teams run a few experiments, pick the one with the best validation accuracy, and ship it. But that's adaptation search without a compass—you're optimizing for accuracy alone, ignoring latency, memory, cost, and auditability.
The real question is: before you train anything, can you predict which adaptation strategy will win?
CalibPlan: Adaptation Planning from Calibration Signals
CalibPlan frames this as an adaptation-planning problem:
Input: A small labeled calibration set (e.g., 100–500 examples)
Output: An adaptation strategy recommendation (e.g., "use RAG," "train a LoRA-4 model," "collect more labels")
Metric: Regret versus exhaustive candidate training
The research question is simple:
Can calibration-time signals reduce adaptation-search regret before model training begins?
Why Calibration Matters
A calibration set is cheap to label. It's small enough that you can afford to be thoughtful about each example. And it's large enough to reveal the structure of your task.
What Calibration Signals Tell You
1. Linear Separability
If your task is linearly separable in embedding space, you don't need fine-tuning. A simple logistic regression on top of frozen embeddings will work. You save training time, memory, and latency.
How to detect it: Train a linear probe on your calibration set. If accuracy is high (>85% on a binary task), the decision boundary is simple.
2. Label Noise
If your labels are noisy, fine-tuning will memorize the noise. You'll see high training accuracy but poor generalization.
How to detect it: Look at the disagreement between your model's predictions and the labels. If the model is confident but wrong, you have label noise. Consider a noise-robust loss or collecting cleaner labels.
3. Class Imbalance
If one class dominates, standard fine-tuning will bias toward the majority class. You'll need weighted losses, resampling, or threshold tuning.
How to detect it: Check the class distribution in your calibration set. If it's skewed (e.g., 90% negative, 10% positive), plan for it upfront.
4. Data Starvation
If your calibration set is tiny relative to the task complexity, fine-tuning will overfit. You need regularization (dropout, weight decay, early stopping) or a simpler model.
How to detect it: Train a small model on your calibration set and measure the gap between training and validation loss. A large gap signals data starvation.
5. Domain Shift
If your calibration set is very different from your deployment data, fine-tuning on calibration alone won't help. You need domain adaptation, transfer learning, or more representative labels.
How to detect it: Compare the feature distributions of your calibration set and a held-out test set. Large divergence signals domain shift.
The Adaptation Strategy Decision Tree
Based on calibration signals, here's a simple decision framework:
Is the task linearly separable?
├─ YES → Use embedding classifier (frozen model + linear probe)
└─ NO → Continue
Is label noise high?
├─ YES → Collect cleaner labels or use noise-robust loss
└─ NO → Continue
Is the class imbalanced?
├─ YES → Plan for weighted loss or resampling
└─ NO → Continue
Is data starved (small calibration set)?
├─ YES → Use parameter-efficient fine-tuning (LoRA, prefix-tuning)
└─ NO → Consider full fine-tuning
Is there domain shift?
├─ YES → Use domain adaptation or retrieval-augmented generation
└─ NO → Standard fine-tuning is reasonable
This tree is not exhaustive, but it captures the most common decision points.
Why This Matters for Small Language Models
Small language models are most valuable when deployment constraints are real: latency, memory, cost, and auditability.
Accuracy alone is not the decision.
A 3B-parameter model that runs in 50ms on a CPU is worth more than a 70B model that requires a GPU cluster, even if the 70B model is 2% more accurate. But you only know this if you've thought about your constraints upfront.
Calibration signals help you:
- Avoid expensive training runs that won't improve accuracy.
- Choose the right model size for your latency budget.
- Plan for inference cost before you commit to fine-tuning.
- Audit your decisions by understanding why you chose a particular strategy.
A Concrete Example: Intent Classification for a Chatbot
Imagine you're building a chatbot for a customer support team. You have 200 labeled examples of customer messages, each tagged with one of 10 intents (e.g., "billing question," "technical support," "complaint").
Step 1: Calibration Analysis
You train a linear probe on frozen embeddings from a small LM (e.g., MiniLM). Accuracy is 82%.
Signal: The task is mostly linearly separable, but not perfectly. A linear classifier alone won't cut it.
Step 2: Check for Label Noise
You sample 20 examples where the model is confident but wrong. You find that 3 are genuinely ambiguous (could be two intents), and 2 are mislabeled.
Signal: Label noise is low (~2.5%), not a blocker.
Step 3: Check Class Balance
You plot the distribution. "Billing question" is 40% of the data, "complaint" is 5%.
Signal: Moderate imbalance. You'll need weighted loss or resampling.
Step 4: Assess Data Starvation
You train a small LoRA model on your 200 examples. Training loss drops to 0.1, but validation loss plateaus at 0.4.
Signal: Data is a bit starved. You could collect more labels, or use stronger regularization.
Step 5: Check Domain Shift
You compare the feature distributions of your 200 labeled examples to 1000 unlabeled examples from production. They're similar.
Signal: No major domain shift. Your calibration set is representative.
Recommendation:
Train a LoRA-2 model with weighted loss (to handle imbalance) and early stopping (to avoid overfitting). This gives you:
- Better accuracy than a linear probe (82% → ~88%).
- Faster inference than full fine-tuning.
- Lower memory footprint than a larger model.
- Auditability: you can explain why you chose LoRA-2 (data starvation signal).
Implementing CalibPlan
Here's a minimal workflow:
1. Collect a small calibration set (100–500 examples, depending on task complexity).
2. Compute calibration signals:
- Train a linear probe on frozen embeddings.
- Measure label noise (disagreement between model and labels).
- Check class balance.
- Measure train-val gap to assess data starvation.
- Compare feature distributions to detect domain shift.
3. Use signals to recommend an adaptation strategy (see decision tree above).
4. Train the recommended model on your full labeled set.
5. Evaluate on a held-out test set and compare to your prediction.
6. Iterate: If your recommendation was wrong, update your decision tree.
The key insight is that steps 2–3 are cheap. You're not training expensive models yet. You're just running diagnostics on a small set of labeled examples.
The Regret Metric
How do you measure whether CalibPlan actually helps?
Define regret as the difference between:
- The accuracy of the strategy recommended by CalibPlan.
- The accuracy of the best strategy found by exhaustive search (training all candidates).
If CalibPlan recommends LoRA-2 and it achieves 88% accuracy, but exhaustive search finds that LoRA-4 achieves 89%, your regret is 1%.
The goal is to minimize regret while avoiding the cost of training all candidates.
In practice, you might find that CalibPlan's recommendation is within 0.5–1% of the best strategy, but saves 70–80% of training time. That's a win.
Open Questions
- How large does the calibration set need to be? Is 100 examples enough? 500? Does it depend on task complexity?
- Can we automate the decision tree? Instead of hand-crafted rules, can we learn a policy that maps calibration signals to strategies?
- How do calibration signals change with model size? Does a 1B model show different signals than a 7B model on the same task?
- Can we use active learning to make calibration more efficient? Instead of random sampling, can we select the most informative examples to label?
Takeaways
- Fine-tuning is not the first step. Calibration is.
- Calibration signals reveal task structure. Use them to guide your adaptation strategy.
- Avoid expensive searches. Train one model, not ten, by planning upfront.
- Accuracy is not the only metric. Consider latency, memory, cost, and auditability.
- Small language models are powerful when constraints are real. Calibration helps you respect those constraints.
The next time you have a new task and a small language model, resist the urge to fine-tune immediately. Spend an hour on calibration. It might save you days of training.
💬 Questions or thoughts? Connect with me on LinkedIn or subscribe to my Substack to discuss adaptation planning, small language models, or deployment constraints.